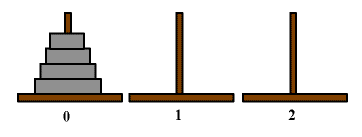
Inhalt |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Unterprogramme sind abgeschlossene Programmteile, die beim Aufruf einen neuen Abschnitt im Stack erzeugen und dort ihre lokalen Variablen ablegen. Nach ihrer Beendigung kehren Unterprogramme genau hinter die Stelle des Aufrufs zurück. Dazu merken sie sich die Rücksprungstelle ebenfalls auf dem Stack.
Obendrein können Unterprogramme Argumente erhalten, die bei jedem Aufruf verschieden sein können. Sie können außerdem einen Wert zurückgeben. Man spricht dann von Funktionen. Wenn die Unterprogramme oder Funktionen im Zusammenhang mit Klassen (dazu später mehr) auftauchen, spricht man von Methoden der Klasse.
Ein typisches Unterprogramm, das keinen Wert zurückgibt, ist etwa
void print (double x)
{
System.out.println("Wert = " + x);
}
Dabei bedeutet void, dass kein Wert zurückgegeben wird. Der Name des Unterprogramms im Beispiel ist print. Das Unterpogramm bekommt ein Argument namens x, der ein double-Wert sein muss. Ein Beispiel für den Aufruf ist
double x = Math.PI; print(x); // druckt: Wert = 3.14152
Die allgemeine Deklaration eines Unterprogramms ist also
ergebnistyp name (parameterliste) anweisungsblock
Dabei ist
ergebnistyp |
Typ des Rückgabewertes, oder void, falls kein Wert zurückgegeben wird. |
name |
Name des Unterprogramms. |
parameterliste |
Mit Komma getrennte Parameter. Jeder Parameter sieht aus wie eine Variablendeklaration und verhält sich auch lokal wie eine Variable. Die Werte für diese Variablen werden beim Aufruf übergeben. |
anweisungsblock |
Mit {...} geklammerte Folge von Anweisungen, jede Anweisung mit ; abgeschlossen. |
Die Bezeichungen Parameter und Argumente werden gewöhnlich auseinandergehalten. Argumente sind die an die Parameter übergebenen Werte.
Merke: Aus Gründen, die erst später klar werden, müssen Unterprogramme, die aus
main aufgerufen werden,
static deklariert werden.
Ein vollständiges Programm sieht also so aus.
public class Test
{ public static void main (String args[])
{
double x=Math.PI;
print(x);
print(x*x);
print(4.5);
}
static void print (double x)
{
System.out.println("Wert = "+x);
}
}
Es kommt also noch der Modifier static hinzu.
print muss also innerhalb der Klasse Test deklariert sein. Dort kann es von main aus einfach mit dem Namen print aufgerufen werden. Wir werden später Unterprogramme in anderen Klassen kennen lernen. Diese werden dann z.B. mit KlassenName.print(x) aufgerufen. In der Tat haben wir solche Aufrufe schon benutzt, etwa bei Math.sqrt().
Wichtig: Man beachte, dass
das x in print nichts
mit dem x im Hauptprogramm main
zu tun hat.
Es ist eine lokale Variable.
Funktionen sind Unterprogramme die nicht den Ergebnistyp void haben. Sie geben einen Wert zurück und lassen sich deshalb in Ausdrücken einsetzen. Ein einfaches Beispiel ist die Funktion x^2.
double sqr (double t)
{
return t*t;
}
Das Ergebnis wird also mit der Anweisung return zurückgegeben. Diese Funktion lässt sich dann wie in beliebigen Ausdrücken verwenden. Im folgenden Beispiel wird der Wert dieses Ausdrucks ausgedruckt.
double x = 1.2;
System.out.println(sqr(x));
System.out.println(sqr(Math.sin(x)) + sqr(Math.cos(x))); // sollte annhähernd 1 ergeben
Man beachte, dass in der dritten Zeile des Beispiels wird Math.sin(x) nur einmal berechnet wird. Verwendet man stattdessen
System.out.println(Math.sin(x)*Math.sin(x));
so wird natürlich der Sinus zweimal berechnet. Man könnte jedoch auch
y = Math.sin(x); System.out.println(y*y);
verwenden. Dies würde dann die Arbeitsweise des Funktionsaufrufs nachahmen, der ebenfalls eine lokale Variable (namens t) verwendet.
Merke: Die Anweisung return beendet die Funktion von jeder Stelle aus - also auch aus Schleifen heraus.
Ein Vorteil von Funktionen ist, dass sie Technik verstecken. Man kann die Funktion ändern, ohne dass der Rest des Programms geändert werden muss. Dazu ein Beispiel.
public class Test
{
public static void main (String args[])
{
String Vorname="Hans", Nachname="Schmidt";
System.out.println(macheName(Vorname,Nachname));
}
public static String macheName
(String vorname, String nachname)
{
return vorname + " " + nachname;
}
}
Die Funktion macheName() bildet einen Namen aus dem Vornamen und dem Nachnamen. Will man den Namen in einer anderen Form haben, so braucht man nur das Unterprogramm zu ändern, und an allen Stellen, an denen es verwendet wird, ändert sich die Funktion des Programms. In obigem Beispiel ist dies nur eine Stelle, aber generell sollte man an Unterprogramme denken, wenn ein Stück Programmcode mehr als einmal verwendet wird.
Im Beispiel wäre etwa folgende Änderung sinnvoll.
public static String macheName
(String vorname, String nachname)
{
return nachname + ", " + vorname;
}
Alle Variablen, die in einer Funktion (oder einem Unterprogramm, was wir nun nicht mehr unterscheiden) deklariert werden, sind lokal und existieren nach dem Ende des Unterprogramms nicht mehr. Sie werden ja auf dem Stack abgelegt, und dieser Bereich wird nach dem Ende des Unterprogramms freigegeben.
Als Beispiel programmieren wir eine Funktion, die x^4 berechet.
double pow4 (double x)
{
double y=x*x;
return y*y;
}
Die Variable y ist lokal. Ebenso der Parameter x, der sich lokal wie eine Variable verhält.
Man beachte nochmals, dass der Name und der Speicherplatz einer lokalen Variablen nichts mit dem aufrufenden Programm zu tun hat, genauso wenig wie der Name und der Speicherplatz von Parametern, die sich einfach wie lokale Variablen des Unterprogramms verhalten.
Parameter sind also lokal. Ihr Speicherplatz hat nichts mit dem aufrufenden Programm zu tun. Parameter sind im Prinzip nur lokale Variablen, denen beim Aufruf gewisse Werte (Argumente) zugewiesen werden. Eine Änderung der Parameter wirkt sich nicht auf das aufrufende Programm aus. Ihr Name ist für das aufrufende Programm unwesentlich.
public class Test
{
public static void main (String args[])
{
int x=4;
test(x);
System.out.println(x);
}
public static void test (int x)
{
System.out.println(x);
x=5;
}
}
Dieses Beispiel druckt zweimal die Zahl 4, einmal im Unterprogramm, und dann nochmals im Hauptprogramm. Dass x im test auf 5 gesetzt wird, wirkt sich nicht auf main aus. Das x in main hat mit dem Parameter x in test nichts zu tun. Lediglich der Wert 4 wird an das Unterprogramm übergeben, und dieser Wert wird dem Parameter x zugeornet. In der Tat ist die Zuweisung x=5 sinnlos.
Parameter werden also immer als Wert (value) übergeben.
In C gibt es eine einfache Möglichkeit, Parameter als Variable bzw. Zeiger auf eine Variable zu übergeben. In diesem Fall ändert sich die Variable, wenn der Parameter im Unterprogramm geändert wird. Dies kann man in Java nur mittels Objekten nachahmen. Allerdings ist insbesondere die Übergabe von Variablen verwirrend und fehlerträchtig, ebenso wie die Übergabe als Zeiger in C.
Falls ein Unterprogramm sich direkt oder indirekt selbst aufruft, spricht man von einem rekursiven Aufruf. Da alle Variablen und Parameter des Unterprogramms lokal sind, stören sich diese nicht mit den Variablen und Parametern des vorigen Aufrufs.
Mit solchen Rekursionen lassen sich sehr elegante Programme erzeugen. Allerdings kostet jeder Aufruf Zeit und Stackplatz. Der Platz auf dem Stack ist auch beschränkt, so dass man aufpassen muss, ihn nicht zu überschreiten. Sonst erhält man eine Exception, die man behandeln muss.
Beispielsweise berechnen wir die Fakultät n!=1*2*...*n rekursiv elegant wie folgt.
double fak (int n)
// Fakultaet rekursiv
{
if (n<=1) return 1.0;
else return n*fak(n-1);
}
Es ist klar, dass hier auch eine iterative Lösung in Frage kommt, die schneller ist und nur den Stackplatz für einen Aufruf benötigt.
double fak (int n)
// Fakultät iterativ
{
double x=1.0;
int i;
for (i=2; i<=n; i++)
{
x=x*i;
}
return x;
}
Diese Lösung sieht aber nicht so elegant aus. Eleganz kann aber auch ein wichtiger Grundpfeiler für Übersichtlichkeit, Wartbarkeit und damit Fehlerfreiheit sein. Manche Programme lassen sich nur mit Hilfe von Rekursion lösen. Wenn die Rekursion aufgrund des beschränkten Platzes auf dem Stack an ihre Grenzen stößt, ahmt man dann Rekursion mit Hilfe von Daten auf Arrays selbst nach. Es ist klar, dass die rekursiven Funktionen diese Aufgabe wesentlich eleganter und durchsichtiger erledigen.
Es ist oft unklar, wie die rekursive Lösung eigentlich funktioniert. In diesem Fall werden die einzelnen Werte von n auf dem Stack zwischengelagert, und zwar von n beginnend rückwärts bis 1. Beim Aufräumen des Stacks werden diese Werte dann benutzt um die Multiplikation 1*2*3*...*n zu berechnen.
Funktionen werden in Java (wie in C++, aber nicht in C) nach ihren Parametertypen (der so genannten Signatur) unterschieden. Der Compiler sucht die korrekte Funktion (bzw. das korrekte Unterprogramm) heraus, das diese Parameter verarbeiten kann.
Funktionen werden aber nicht nach ihrem Ergebnistyp unterschieden.
public class Test
{
public static void main (String args[])
{
print(3.4); // druckt: double-wert 3.4
print(3); // druckt: int-wert 3
}
static void print (double x)
{
System.out.println("double-Wert "+x);
}
static void print (int n)
{
System.out.println("int-Wert "+n);
}
}
Die beiden Unterprogramme heißen gleich. Der Compiler (oder der Interpreter) unterscheiden die Funktionen nach dem Typ der Parameter-Werte. (Funktionen, die sich nur im Ergebnistyp unterscheiden, erzeugen eine Fehlermeldung.)
Natürlich kann eine Funktion auch ein Array zurückgeben. Das sieht dann so aus.
static double[] generate (int n)
// gib ein Array mit n Zufallsvariablen zurück.
{
double R[]=new double[n];
int i;
for (i=0; i<n; i++) R[i]=Math.random();
return R;
}
Der Ergebnistyp wird also wie eine Array-Deklaration ohne Namen geschrieben. Das Programm gibt natürlich nur eine Referenz auf das Array zurück. Das Array selbst befindet sich ja auf dem Heap. Man erinnere sich daran, das Elemente auf dem Heap automatisch beseitigt werden, wenn sie nicht mehr benötigt werden.
Man kann auch ein Array (genauer eine Referenz darauf) als Parameter an eine Funktion übergeben. Als Beispiel schreiben wir Unterprogramme, die den Mittelwert und die Standardabweichung berechnen. Hier ein vollständiges Programm.
public class Test
{
public static void main(String args[])
{
double R[] = generate(1000);
double m = mean(R);
System.out.println("Mean value " + m);
System.out.println("Standard Deviation " + deviation(R, m));
}
static double[] generate(int n)
// generiere Zufallsvektor der Länge n
{
double R[] = new double[n];
int i;
for (i = 0; i < n; i++)
R[i] = Math.random();
return R;
}
static double mean(double x[])
// berechne Mittelwert von x
{
int n = x.length, i;
double sum = 0;
for (i = 0; i < n; i++)
sum += x[i];
return sum / n;
}
static double deviation(double x[], double mean)
// berechne Standard-Abweichung von x, wenn der Mittelwert
// bekannt ist
{
int n = x.length, i;
double sum = 0;
for (i = 0; i < n; i++)
sum += sqr(x[i] - mean);
return Math.sqrt(sum / (n - 1));
}
static double sqr(double x)
// Hilfsfunktion, berechne x^2
{
return x * x;
}
}
Man beachte, dass nur ein einziges Array existiert. Alles, was übergeben oder zurückgegeben wird, sind nur Referenzen auf dieses Array.
Wir haben bisher lediglich lokale Variablen in Unterprogrammen und Funktionen verwendet. Dies entspricht auch dem guten Stil der funktionellen Programmierung. Es gibt aber auch globale Variablen, die von jedem Unterprogramm aus aufgerufen werden können. Da wir bisher nur statische Funktionen der Klasse definiert haben, müssen diese globalen Variablen auch statisch sein.
Im folgenden Beispiel haben wir eine Zähler count global und statisch definiert. Dieser Zähler soll zählen, wie oft die Funktion f(x) aufgerufen wurde, deren Nullstelle zwischen 1 und 2 wir mit dem Sekantenverfahren ermitteln wollen.
public class Test
{
// Zähler für die Anzahl der Funktionsaufrufe public static int count = 0; public static double f(double x) { count++; return x * x * x - x - 1.0; } public static void main(String args[]) { // Berechne Nullstelle von f mit dem Sekantenverfahren double xa = 1.0, xb = 2.0, ya = f(xa), yb = f(xb); while (Math.abs(yb) > 1.0e-10) { double xnew = (xa * yb - xb * ya) / (yb - ya); xa = xb; xb = xnew; ya = yb; yb = f(xb); } System.out.println("Ergebnis : " + xb); System.out.println("Nach " + count + " Funktionsaufrufen"); } }
Das Ergebnis sieht so aus:
Ergebnis : 1.324717957244746 Nach 10 Funktionsaufrufen
Es zeigt, dass nur 10 Funktionsaufrufe für eine 14-stellige Genauigkeit ausreichen. Das Sekantenverfahren ist ein sehr gutes Verfahren zur Bestimmung von Nullstellen.
Java beinhaltet eine automatisch Erzeugung der Dokumentation von Funktionen und Klassen. Wird sie genutzt, so steht sie in Entwicklungsumgebungen zur Verfügung. Mit der Maus über einem Funktionsnamen wird dann zum Beispiel die Dokumentation angezeigt.
Die dazu notwendigen Kommentare beginnen mit /** und enden mit */. Sie können @-Parameter enthalten. Eclipse erzeugt einen leeren Kommentar automatisch, wenn /** mit Return eingegeben wurde. Man beachte, dass es einfache Kommentarblöcke gibt die mit /* anfangen und mit */ enden.
/** * Testklasse zur Demonstration des Sekantenverfahrens. * @author reneg */ public class Test { /** * Zähler. */ public static int count = 0; /** * Funktion deren Nullstelle bestimmt werden soll. * @param x * @return f(x) */ public static double f(double x) { count++; return x * x * x - x - 1.0; } /** * Berechne Nullstelle von f mit dem Sekantenverfahren. * @param args (nicht verwendet) */ public static void main(String args[]) { double xa = 1.0, xb = 2.0, ya = f(xa), yb = f(xb); while (Math.abs(yb-ya) > 1.0e-20) { double xnew = (xa * yb - xb * ya) / (yb - ya); xa = xb; xb = xnew; ya = yb; yb = f(xb); } System.out.println("Ergebnis : " + xb); System.out.println("Funktionswert : " + f(xb)); System.out.println("Nach " + count + " Funktionsaufrufen"); } }
Es ist eher unüblich, auch Variablen mit JavaDoc-Kommentaren zu versehen. Meist verwendet man hier nur //-Kommentare.
Hier noch einmal das Bisektionsverfahren mit Funktionen. Das Programm sieht dann viel klarer aus.
public class Test
{
public static void main (String args[])
{
System.out.println(bisect(0,1));
}
static double bisect (double a, double b)
// Bisektionsverfahren für die Funktion x
{
double m,y;
while (b-a>1e-13) // Abbruch, wenn Intervall klein genug
{
m=(a+b)/2; // Berechne Mitte
y=f(m); // und Wert in der Mitte
if (y>0) a=m; // Nimm rechtes Halb-Intervall
else b=m; // Nimm linkes Halb-Intervall
}
return (a+b)/2;
}
static double f (double x)
// Funktion, deren Nullstelle berechnet wird
{
return Math.exp(x)-4*x;
}
}
Der Nachteil ist, dass die Funktion f, deren Nullstelle zu berechnen ist, nicht so leicht an die Funktion bisekt übergeben werden kann (im Unterschied zu C). Es gibt aber dafür verschiedene Auswege.
Es gibt Probleme, die sich fast nur mit Rekursion lösen lassen. Eines davon ist das Problem der Türme von Hanoi.
Die Ausgangssituation sei hier skizziert.
Die Aufgabe besteht darin, die Scheiben von links (Turm 0) in die Mitte (Turm 1) zu bewegen. Dabei darf immer nur eine Scheibe bewegt werden, und nie darf eine größere über einer kleineren liegen.
Die rekursive Lösung besteht darin, zuerst 3 Scheiben von 0 nach 2 zu bewegen, und dann die unterste nach 1. Danach wieder 3 Scheiben von 2 nach 1. Also kann man 4 Scheiben bewegen, wenn man weiß, wie 3 Scheiben bewegt werden. Dies lässt sich in folgendem Programm umsetzen.
public class Test
{
public static void main (String args[])
{
hanoi(4,1,2,3); // bewege 4 Scheiben von 0 nach 1
}
static void hanoi (int n, int from, int to, int using)
// Bewegt n Scheiben von from nach to, wobei using frei ist.
{
if (n==1)
{
System.out.println("Move disk from "+from+" to "+to);
}
else
{
hanoi(n-1,from,using,to);
System.out.println("Move disk from "+from+" to "+to);
hanoi(n-1,using,to,from);
}
}
}
Die Ausgabe des Programms ist eine Folge von Anweisungen, von wo nach wo die nächste Scheibe zu verschieben ist.
Move disk from 1 to 3 Move disk from 1 to 2 Move disk from 3 to 2 Move disk from 1 to 3 Move disk from 2 to 1 Move disk from 2 to 3 Move disk from 1 to 3 Move disk from 1 to 2 Move disk from 3 to 2 Move disk from 3 to 1 Move disk from 2 to 1 Move disk from 3 to 2 Move disk from 1 to 3 Move disk from 1 to 2 Move disk from 3 to 2
Das Programm sieht leicht aus, ist aber wohl am Anfang schwer zu verstehen.
Als Beispiel für einen schnellen Sortier-Algorithmus geben wir hier das Quicksort-Verfahren an. Die Logik des Programms ist etwas schwer zu verstehen.
Der verwendete Algorithmus ist folgender:
Dies ist natürlich ein rekursives Verfahren.
public class Test
{
static public void main(String args[])
{
int n = 100;
double v[] = new double[n];
int i;
for (i = 0; i < n; i++)
v[i] = Math.random(); // n Zufallszahlen
QuickSort(v, 0, n - 1); // sortieren
for (i = 0; i < n; i++)
System.out.println(v[i]);
// und ausgeben.
}
static void QuickSort(double a[], int loEnd, int hiEnd)
// Sortiere den Abschnitt zwischen a[loEnd] und a[hiEnd]
{
int lo = loEnd;
int hi = hiEnd;
double mid;
if (hiEnd > loEnd) // sonst ist nichts zu tun!
{
mid = a[(loEnd + hiEnd) / 2];
// nimm mittelgrosses Element (hoffentlich)
// Trenne in kleinere und groessere:
while (lo <= hi)
{
while ((lo < hiEnd) && (a[lo] < mid))
lo++;
// von links aussen nach rechts,
// solange nichts zu tun ist
while ((hi > loEnd) && (a[hi] > mid))
hi--;
// von rechts aussen nach links
// solange nichts zu tun ist
if (lo <= hi) // zwei Elemente stehen falsch!
{
swap(a, lo, hi); // vertauschen
lo++; // nun stehen sie richtig
hi--;
}
}
// Sortiere rechts:
if (loEnd < hi)
QuickSort(a, loEnd, hi);
// Sortiere alles kleiner mid
if (lo < hiEnd)
QuickSort(a, lo, hiEnd);
// Sortiere alles groesser mid
}
}
static void swap(double a[], int i, int j)
// Vertausche im a[i] mit a[j]
{
double h;
h = a[i];
a[i] = a[j];
a[j] = h;
}
}
Wie kann man nun Daten in einem sortierten Array finden? Dies geht recht schnell durch ein Intervallteilungsverfahren. Wenn man eine Zahl im Arraybereich i bis j sucht, so kann man die Zahl mit dem Element in der Mitte (i+j)/2 vergleichen und dadurch den Bereich in zwei Teile aufspalten.
static int binSearch (double v[], double x)
// search the sorted double array for x
{
return binSearch(v,x,0,v.length);
}
static int binSearch (double v[], double x, int i, int j)
// search the sorted double array for x between i and j-1
{
int k=(i+j)/2;
if (v[k]==x) return k;
else if (k==i) return -1;
else if (v[k]>x) return binSearch(v,x,i,k);
else return binSearch(v,x,k,j);
}
Der Algorithmus wird am einfachsten rekursiv programmiert. Dazu übergibt man das zu durchsuchende double-Array, den zu suchenden Wert und die Intervallgrenzen i und j für die Indizes. Dann wird ein mittlerer Index k=(i+j)/2 berechnet, und getestet, ob dieser Index gleich dem gesuchten Wert ist. Ansonsten wird rechts oder links gesucht.
Beachten Sie, dass der Algorithmus abbrechen muss. Dies ist der Fall wenn j gleich i+1 wird. In diesem Fall wird k gleich i, und wir übergeben -1, was "nicht gefunden" bedeuten soll. Es ist wichtig, in welcher Reihenfolge die Tests vorgenommen werden.
Dieses Beispiel ist nur wohl für Mathematiker verständlich, da die Multiplikation von Matrizen bekannt sein muss. Sei A eine quadratische Matrix. Wir berechnen A^n für große n. Der verwendete Algorithmus setzt
An=(An/2)2
wenn n gerade ist, bzw.
An=A*(A(n-1)/2)2
falls n ungerade ist. Dies funktioniert natürlich rekursiv und ist ein sehr effektives Verfahren.
Das Programm nimmt als Beispiel eine spezielle Matrix, deren Potenzen mit den Fibonacci-Zahlen zusammenhängen.
Man sieht hier auch, wie zweidimensionale Arrays als Parameter und als Rückgabewerte verwendet werden. Die Größe der Arrays wird nicht mit übergeben, sondern mittels length ausgelesen. Man beachte, dass die Spaltenzahl einer quadratischen Matrix die Größe von a[0] (das ist die erste Zeile von a) ist.
Wir verwenden dieses Mal JavaDoc-Kommentare, wie es sich gehört.
/** * Demonstration der Potenzen von Matrizen mit Rekursion * * @author reneg */ public class Test { static public void main(String args[]) { double A[][] = { { 0, 1 }, { 1, 1 } }; double B[][] = pot(A, 100); print(B); // drucke A^n System.out.println(B[0][0] + B[0][1]); // druckt 5.731478440138171E20 System.out.println(fibonacci(100)); // druckt dasselbe } /** * Berechne A^n mit dem Verfahren der sukzessiven Quadrierung * * @param A Quadratische Matrix * @param n Potenz * @return A^n */ static double[][] pot(double a[][], int n) { if (n == 1) return a; if (n % 2 == 0) return sqr(pot(a, n / 2)); else return mult(sqr(pot(a, n / 2)), a); } /** * Berechne das Produkt zweier Matrizen * * @param A * @param B * @return A*B */ static double[][] mult(double a[][], double b[][]) { double c[][] = new double[a.length][b[0].length]; int i, j, k; for (i = 0; i < a.length; i++) for (j = 0; j < b[0].length; j++) { c[i][j] = 0; for (k = 0; k < b.length; k++) c[i][j] += a[i][k] * b[k][j]; } return c; } /** * Berechne A*A * * @param A * @return A^2 */ static double[][] sqr(double a[][]) { return mult(a, a); } /** * Drucke eine Matrix. * * @param a */ static void print(double a[][]) { int i, j; for (i = 0; i < a.length; i++) { for (j = 0; j < a[i].length; j++) System.out.print(a[i][j] + " "); System.out.println(""); } } /** * Berechne n-te Fibonacci-Zahl * * @param n * @return F_n */ static double fibonacci(int n) { int i; double a = 0, b = 1, old; for (i = 0; i < n; i++) { old = b; b = a + b; a = old; } return b; } }
Eines der faszinierensten Beispiele für rekursive Programmierung ist das Sortierverfahren Merge Sort. Tatsächlich kann es auch beim manuellen Sortieren verwendet werden. Es ist das schnellste bekannte Verfahren zum allgemeinen Sortieren.
Die rekursive Bechreibung ist ganz einfach. Wir teilen den zu sortierenden Stapel in zwei Hälften, sortieren jede Hälfte und vereinigen (merge) die beiden sortierten Hälften wieder. Diese Vereinigung ist einfach, da wir nur die jeweils kleinere Karte von einem der beiden Stapel ziehen müssen, bis ein Stapel leer ist. Die Rekursion entsteht natürlich, weil wir die beiden Hälften mit dem selben Algorithmus sortieren.
class MergeSorter
{
// needed as working space
String[] work;
public void sort (String[] array)
{
if (array.length < 2)
return;
// create work space
work = new String[array.length];
// call recursive sort
sort(array, 0, array.length - 1);
}
void sort (String[] array, int start, int end)
{
// System.out.println(start + "-" + end);
// half point, can be equal to start or end.
int half = (start + end) / 2;
if (half - start > 0) // need to sort first half
sort(array, start, half);
if (end - (half + 1) > 0) // need to sort second half
sort(array, half + 1, end);
// merge sorted parts
merge(array, start, half, half + 1, end);
}
void merge (String[] array, int start1, int end1, int start2, int end2)
{
// aim index to copy into work
int aim = start1;
// remember start index, because we are changing start1
int start = start1;
// Loop breaks if one merge part is exceeded
while (true)
{
if (array[start1].compareTo(array[start2]) < 0)
{
work[aim++] = array[start1++];
if (start1 > end1) // first part is exceeded
{
while (start2 <= end2)
work[aim++] = array[start2++];
break;
}
}
else
{
work[aim++] = array[start2++];
if (start2 > end2) // second part is exceeded
{
while (start1 <= end1)
work[aim++] = array[start1++];
break;
}
}
}
System.arraycopy(work, start, array, start, aim - start);
}
}
public class Test
{
public static void main (String args[]) throws Exception
{
// Create 10 million strings
int N = 10000000;
String[] array = new String[N];
for (int i = 0; i < N; i++)
array[i] = "String " + Math.random();
// create sorter
MergeSorter sorter = new MergeSorter();
// sort with time measurement
long time = System.currentTimeMillis();
sorter.sort(array);
// Arrays.sort(array); // compare to system sort
System.out.println((System.currentTimeMillis() - time) + " msec");
// Check sort
for (int i = 0; i < N - 1; i++)
if (array[i].compareTo(array[i + 1]) > 0)
throw new Exception("Error in Sort");
}
}
Der Aufruf im Hauptprogramm, eingeschlossen in die Zeitmessung, wird im MergeSorter in eine rekursive Funktion umgeleitet. Die Funktion merge ist ziemlich einfach zu implementieren, wenn man den hier gezeigten Schleifenansatz mit einer Dauerschleife verwendet. Die Strings werden im Arbeitsarray work abgelegt und von dort wieder ins Orignalarray mit System.arraycopy kopiert. Das ist etwas schneller als das Kopieren mit for-Schleife.
Der Algorithmus benötigt für 10 Millionen Strings etwa 10 Sekunden. Für normale Arraylängen ist er sehr, sehr schnell. Der interne Algorithmus liegt im gleichen Rahmen.
Der MergeSorter funktioniert so mit dem bestimmten Datentyp String und müsste für andere Datentypen umgeschrieben werden. Wir werden aber später generische Datentypen und Interfaces kennen lernen, die eine flexiblere Implementation erlauben.